Learning an Actionable Discrete Diffusion Policy via Large-Scale Actionless Video Pre-Training
Our trained agent VPDD can complete a wide range of tasks in MetaWorld and RLBench:
Abstract
Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. However, it remains a challenge due to the domain gap between humans and robots. Moreover, it is difficult to extract useful information representing the dynamic world from human videos, because of its noisy and multimodal data structure.
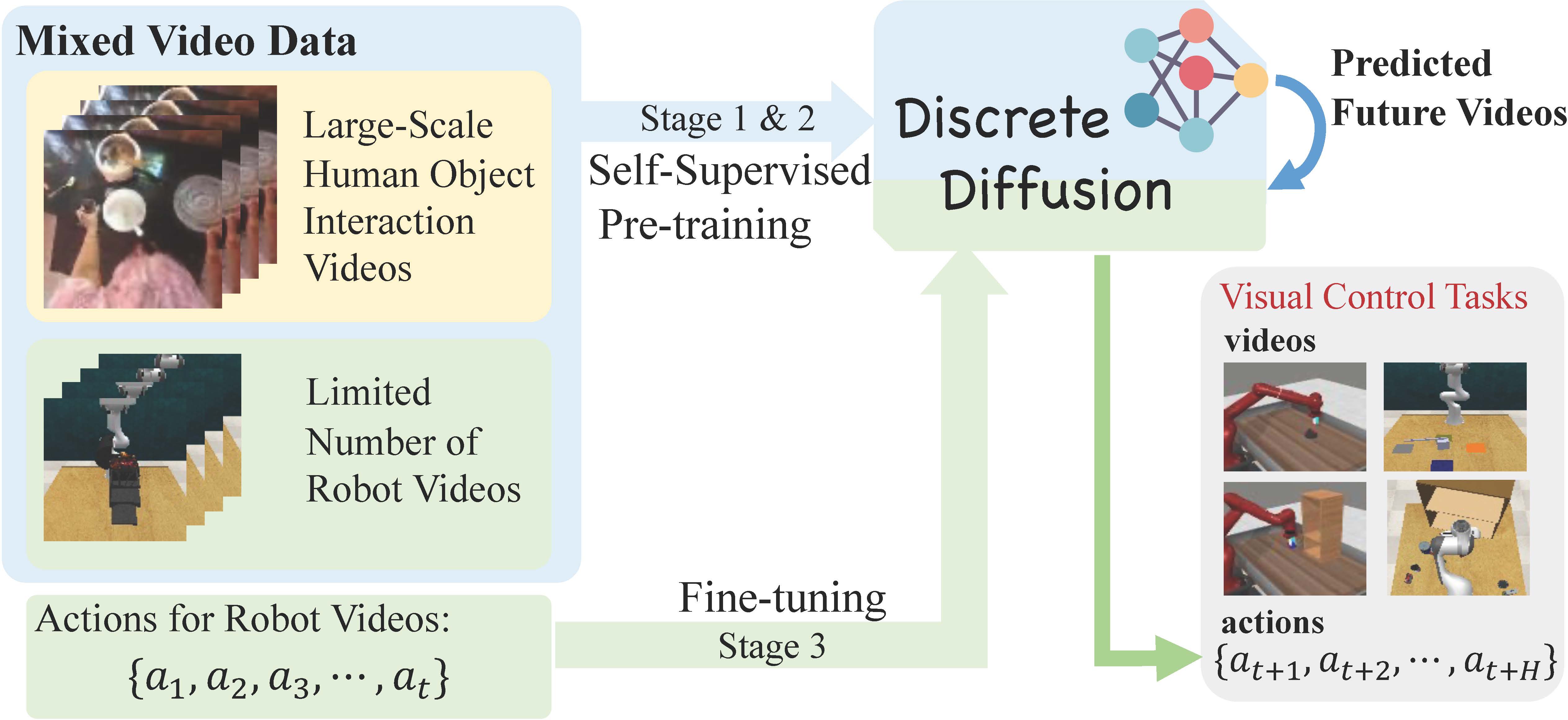
In this paper, we introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by learning compressed visual representations from both human and robot videos to obtain unified video tokens. In the pretraining stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space.
In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning trained on a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches.
Method
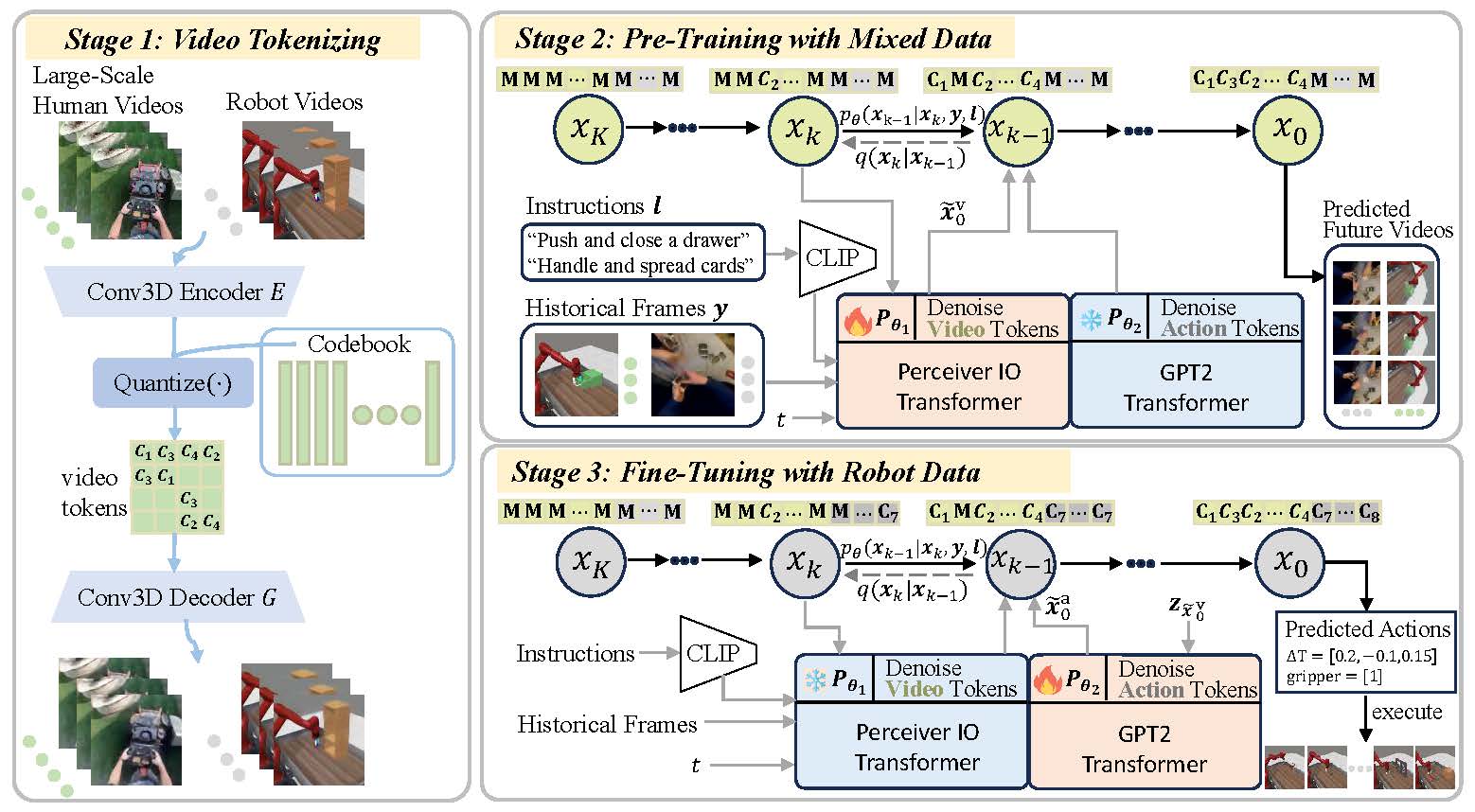
The overall pipeline of VPDD. A video-based VQ-VAE is leveraged to encode both human and robot videos into discrete latent codes. Subsequently, a unified discrete diffusion is firstly pre-trained on these video latent codes via a self-supervised objective, predicting future videos conditioning on language instructions and historical videos. The pre-trained video prediction model \(p_{\theta_1}\) can capture temporal dynamics and representations of the current task. Lastly, we fine-tune our diffusion model on a limited number of robot data. In each diffusion step of the fine-tuning stage, we leverage \(p_{\theta_1}\) to provide hidden representations \(z_{\widetilde{x}_{0}^{v}}\) to accelerate downstream action learning with video foresight. Both video prediction and action learning are executed simultaneously through our unified objective.
VPDD can generate consistent videos in the egocentric Ego4d domain. Below, we show some generated video clips with 32 frames to show the video prediction performance of our method.
After the pre-training, VPDD exhibits the capability to generate future video clips across diverse tasks while maintaining dynamic consistency.
Each synthesized video clip consists of 4 frames, and serves as a strong guidance to enable efficient policy learning for downstream tasks.
To demonstrate the dynamic consistency and accurate prediction of future behavior in the generated video clips by VPDD \(p_{\theta_1}\), we conduct multiple inferences and concatenate the resulting video clips to create an 8-second video. Below, we provide some examples observed in MetaWorld: We additionally fine-tune our pre-trained \(p_{\theta_1}\) on real robot videos with various embodiments to demonstrate the efficacy of our method in real environments. Subsequently, we concatenate the predicted video clips to formulate a 16-second coherent video. Below, we provide examples observed in the real environment:
Below, we illustrate some video clips on Meta-World.
VPDD also demonstrates the ability to generate multi-view videos while ensuring view correspondence. Below, we illustrate some video clips on RLBench.
BibTeX
@inproceedings{he2024learning,
title={Learning an Actionable Discrete Diffusion Policy via Large-Scale Actionless Video Pre-Training},
author={He, Haoran and Bai, Chenjia and Pan, Ling and Zhang, Weinan and Zhao, Bin and Li, Xuelong},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
}
}